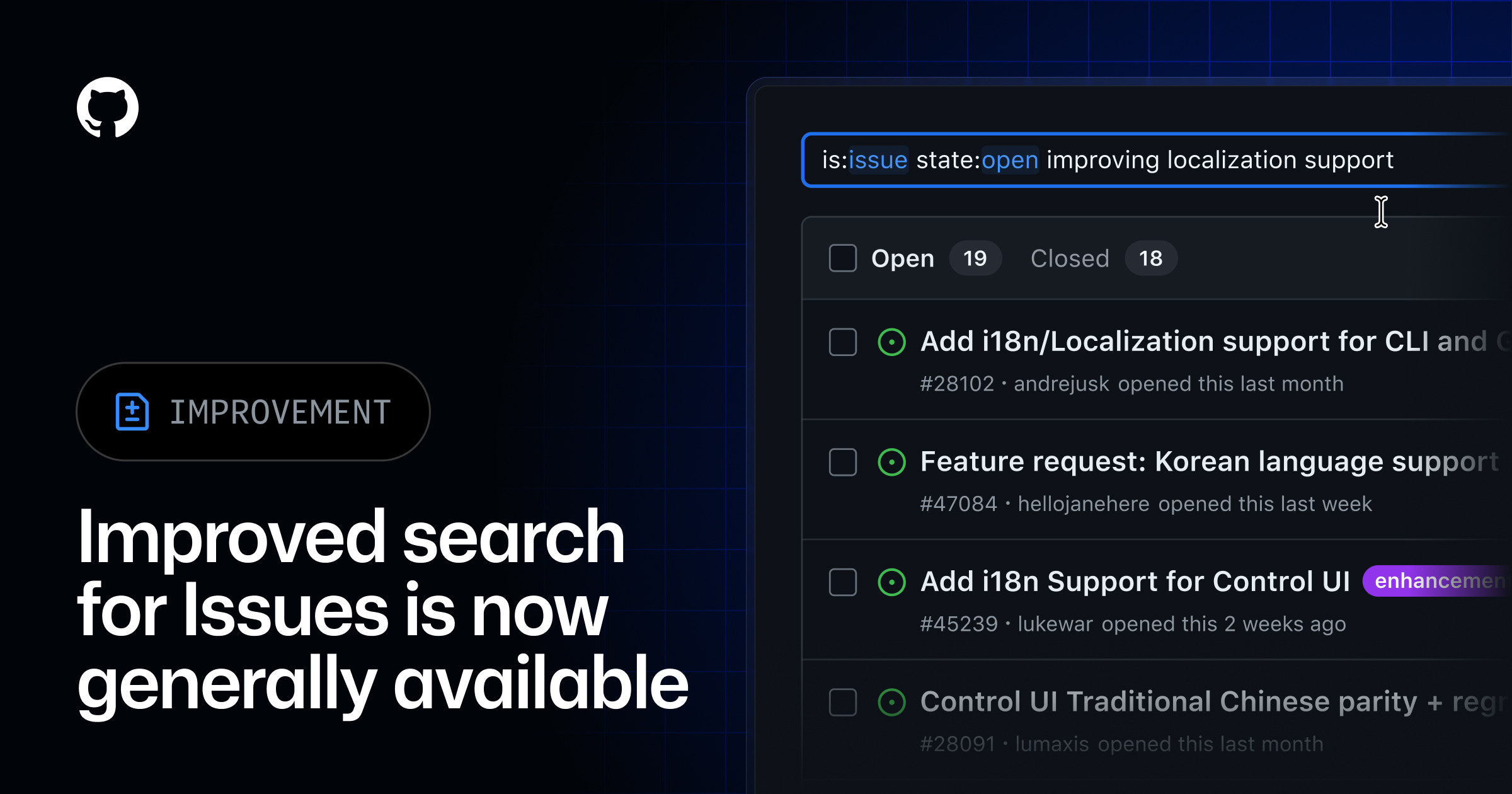
GitHub Issues mejora su búsqueda semántica y abre API para equipos
GitHub llevó a GA su nueva búsqueda de Issues con modo semántico e híbrido, incluyendo acceso por API. El cambio impacta la gestión de backlog, triage y automatizaciones en equipos de plataforma y DevOps.
Introducción
La gestión de incidencias en equipos de plataforma depende de una premisa simple: encontrar rápido el ticket correcto. Cuando un backlog escala y aparecen miles de issues entre repos, la búsqueda tradicional por palabra exacta suele generar ruido, tickets duplicados y triage más lento. GitHub acaba de mover a disponibilidad general su búsqueda mejorada de Issues, incorporando coincidencia semántica e integración por API, con impacto directo en operaciones técnicas.
Qué ocurrió
Según el changelog oficial de GitHub (2 de abril de 2026), la búsqueda mejorada de Issues pasa de preview a GA. La función indexa títulos y cuerpos para devolver resultados por significado, no solo por coincidencia lexical. Además, el feature llega a dashboard multi-repo y se habilita en API REST/GraphQL mediante parámetros de tipo de búsqueda (semantic/hybrid).
GitHub reporta una mejora de eficacia interna: cuando el usuario encontró resultado útil, apareció en el top 3 un 75% de las veces, versus 66% del modelo tradicional. Ese dato no reemplaza medición local, pero muestra una tendencia concreta: menos tiempo para identificar contexto en incidentes repetidos, regresiones y deuda operativa escondida en historial de issues.
Impacto para DevOps / Infraestructura / Cloud / Seguridad
Para DevOps, SRE y plataforma, el cambio pega en el día a día. Primero, mejora el triage inicial porque un operador puede describir un síntoma en lenguaje natural y recuperar issues relacionados aunque no compartan términos exactos. Segundo, reduce duplicación de tickets en incidentes recurrentes: si la búsqueda trae antecedentes relevantes, el equipo enlaza o reabre en vez de crear ruido nuevo.
Tercero, habilita automatización más rica. Al estar disponible por API, una pipeline o bot interno puede consultar issues semánticamente antes de crear uno nuevo, clasificar incidentes por similitud o sugerir runbooks vinculados a casos previos. Cuarto, cambia la gobernanza del backlog: con best match por defecto y modo híbrido, la calidad del texto en títulos y plantillas pasa a ser un activo operacional.
Detalles técnicos
El anuncio incluye capacidades y límites técnicos que conviene considerar en diseño operativo:
– Modo semántico e híbrido: en el endpoint /search/issues se puede indicar search_type=semantic o search_type=hybrid; si no se define, permanece lexical.
– Alcance por calificadores: se mantienen repo:, org:, user: para limitar contexto y mejorar relevancia en organizaciones grandes.
– Rate limit específico: consultas semánticas/híbridas tienen límite más bajo (10 req/min según changelog) respecto de búsquedas tradicionales.
– Fallback explícito: la respuesta API indica tipo de búsqueda aplicada y motivo de fallback cuando ocurre degradación a lexical.
– Compatibilidad GraphQL: el argumento searchType permite SEMANTIC o HYBRID para integrar en flujos existentes.
Desde una mirada de plataforma, esto obliga a diseñar caché, ventanas de consulta y políticas de reintento para no saturar límites cuando se integra en bots de triage o asistentes internos.
Qué deberían hacer los administradores o equipos técnicos
1) Revisar automatizaciones que crean issues: antes de abrir tickets, agregar consulta semántica/híbrida para detectar duplicados o historial relevante.
2) Ajustar plantillas de incidentes: títulos y descripciones con contexto técnico aumentan precisión de recuperación.
3) Definir scopes por equipo: usar repo/org para evitar resultados irrelevantes en organizaciones con portfolios grandes.
4) Medir KPIs operativos: tiempo de triage, tasa de duplicados, tiempo a primer contexto útil y tickets reabiertos por mala clasificación.
5) Controlar límites API: implementar backoff y batching en integraciones para respetar rate limits de búsqueda avanzada.
La oportunidad no está solo en buscar mejor, sino en usar esa búsqueda para endurecer procesos de incident management y hygiene del backlog.
Conclusión
La GA de búsqueda semántica en GitHub Issues es una mejora silenciosa pero importante para operación técnica. No es una revolución por sí sola, pero sí una pieza de alto impacto en organizaciones que viven del tiempo de respuesta y de la calidad de su backlog.
Bien aplicada, puede bajar fricción entre desarrollo y operaciones, reducir duplicados y acelerar diagnóstico. Mal aplicada, puede transformarse en otra feature sin métricas. La clave es combinar funcionalidad nueva con disciplina de proceso y observabilidad del propio flujo de trabajo.
Fuentes
Notas operativas adicionales para equipos de guardia
Un aspecto poco visible de esta mejora es su efecto en los turnos on-call. Cuando la persona de guardia no participó en el incidente original, la recuperación semántica de issues puede acortar mucho la fase de contexto. En lugar de depender de memoria tribal o de etiquetas inconsistentes, el equipo puede ubicar antecedentes funcionalmente similares y reutilizar diagnóstico, workarounds y decisiones previas. Esto también mejora handoffs entre zonas horarias y reduce variabilidad en la respuesta.
Para capturar ese beneficio, conviene acordar una política mínima de cierre de issues operativos: documentar causa probable, componente afectado, mitigación aplicada y enlace a evidencias. Sin esa disciplina, la búsqueda semántica tendrá menos material útil para correlacionar. En otras palabras, la nueva capacidad es potente, pero su retorno depende de la calidad de datos que los propios equipos dejan en su historial operativo.