GitHub liberó Actions Runner Controller 0.14.0 con cambios que afectan de forma directa cómo los equipos de plataforma gestionan runners self-hosted en Kubernetes: multilabel en scale sets, nuevo cliente actions/scaleset, mayor control de metadatos internos y ajustes de autoscaling para evitar entornos desactualizados.
Introducción
Para muchas organizaciones, GitHub Actions dejó de ser solo una herramienta de CI/CD y pasó a convertirse en una pieza crítica de su plataforma de entrega. En ese escenario, los runners self-hosted sobre Kubernetes son cada vez más frecuentes porque permiten controlar costos, topología de red, aislamiento, cumplimiento normativo y performance en pipelines complejos. Por eso, los cambios en Actions Runner Controller (ARC) no son menores: modifican el comportamiento operativo de una capa sensible para desarrollo y operaciones.
La publicación de ARC 0.14.0 introduce mejoras que atacan varios dolores comunes de equipos DevOps y Platform Engineering: proliferación de scale sets por etiquetado limitado, dificultad para estandarizar metadatos en recursos internos, fricción para construir autoscaling personalizado y riesgo de ejecutar jobs sobre configuraciones de runner desfasadas. Aunque no es un “cambio disruptivo” de arquitectura, sí representa una actualización de alto valor práctico para clusters que ya operan ARC en producción.
Qué ocurrió
GitHub anunció la disponibilidad general de ARC 0.14.0 y detalló seis cambios principales. El primero, y probablemente más visible, es el soporte de multilabel para runner scale sets. Hasta ahora, muchas implementaciones terminaban creando múltiples scale sets para combinar atributos como sistema operativo, nivel de hardware, zona de cumplimiento o conectividad privada. Con multilabel, un único scale set puede cubrir combinaciones más ricas de criterios en runs-on.
Además, ARC pasa a usar como cliente principal la librería pública actions/scaleset, reemplazando el cliente interno previo. Esto no solo impacta al controlador oficial: también abre la puerta a integraciones personalizadas con una base más consistente para proveedores internos de plataforma. En paralelo, se agregan opciones para aplicar labels y annotations personalizadas sobre recursos internos administrados por ARC (roles, role bindings, service accounts y listener pods), y se publican charts Helm experimentales con estructura más limpia y mejor soporte de configuración.
También hay cambios en comportamiento de escalado: ARC puede detener el autoscaling de un runner set cuando detecta configuración desactualizada, reduciendo el riesgo de que se sigan aprovisionando runners inconsistentes durante una ventana de rollout. Finalmente, el listener incorpora por defecto nodeSelector kubernetes.io/os=linux, una medida operativa útil para clusters mixtos Linux/Windows donde antes podían ocurrir errores de scheduling evitables.
Impacto para DevOps / Infraestructura / Cloud / Seguridad
El impacto técnico es concreto en operación diaria. En primer lugar, el soporte multilabel reduce complejidad administrativa: menos scale sets implica menos objetos a gobernar, menos drift y menor superficie de errores de configuración. En organizaciones con muchos repositorios y equipos, esto simplifica la asignación de capacidad y la trazabilidad de qué runners reciben cada tipo de carga.
En segundo lugar, el uso del cliente actions/scaleset mejora la alineación entre el comportamiento del controlador y posibles extensiones internas. Para equipos de plataforma que construyen tooling propio (por ejemplo, políticas de escalado según presupuesto, ventana horaria o criticidad del pipeline), este punto reduce fricción de integración y evita depender de implementaciones privadas difíciles de mantener.
Tercero, la capacidad de personalizar metadatos de recursos internos facilita observabilidad y compliance. En Kubernetes, la consistencia de labels/annotations es clave para políticas de seguridad, inventario, chargeback y auditoría. Poder aplicar convenciones corporativas directamente desde charts reduce tareas manuales y evita excepciones que luego complican auditorías.
Por último, los ajustes de autoscaling y scheduling mejoran resiliencia operativa. Frenar escalado sobre configuraciones obsoletas evita ejecutar jobs en entornos potencialmente inconsistentes, y forzar listener en Linux por defecto previene fallos silenciosos en clusters heterogéneos. No es una mejora “de marketing”: reduce incidentes reales de plataforma.
Detalles técnicos
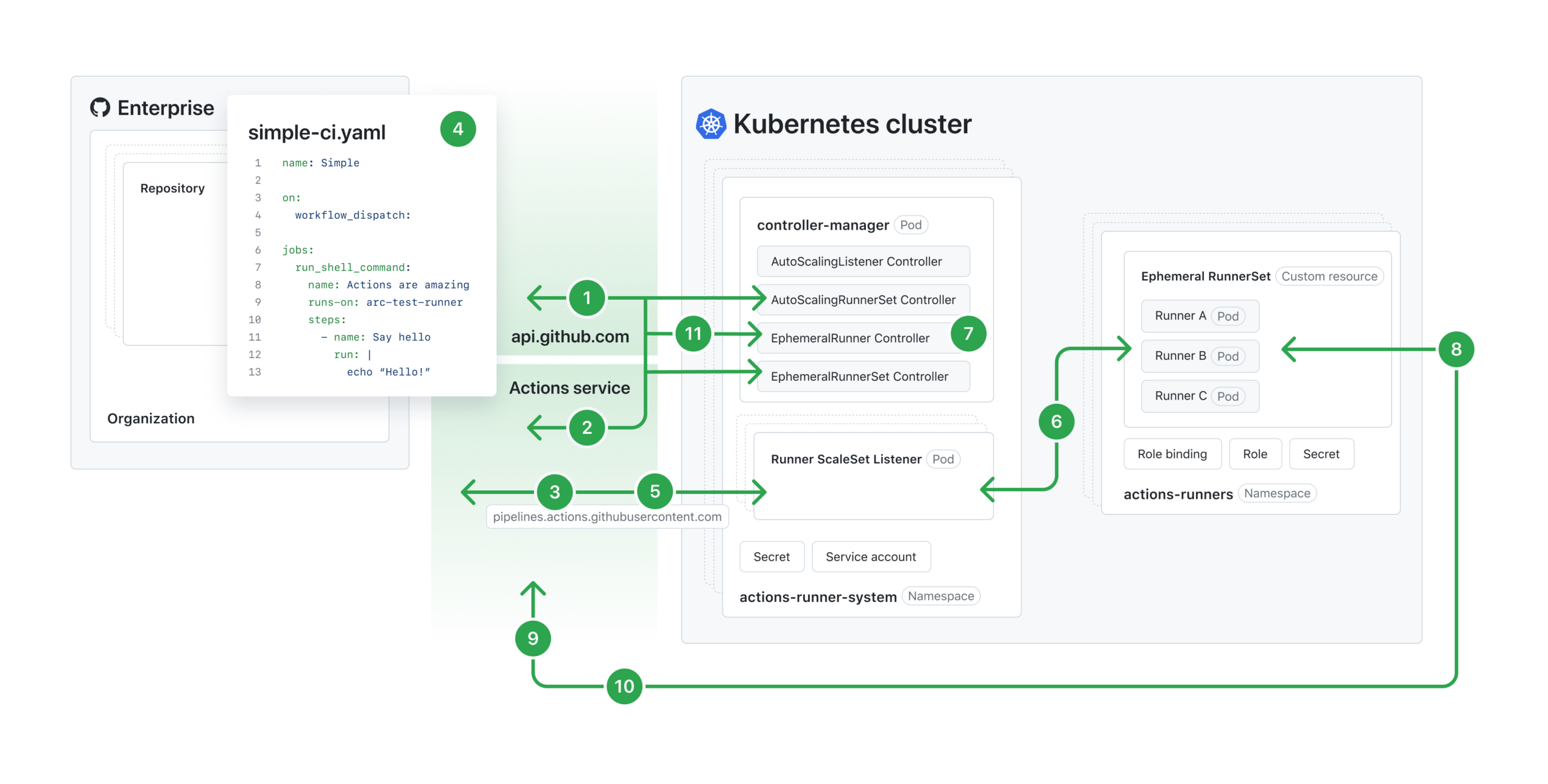
Desde la documentación de GitHub, ARC opera como un operador de Kubernetes que orquesta runner scale sets efímeros con autoscaling basado en demanda de jobs. El modelo de trabajo depende de componentes como AutoScalingRunnerSet, listener pods y EphemeralRunnerSet, más intercambio continuo con la API de GitHub Actions para registrar y despachar runners.
Sobre esa base, ARC 0.14.0 introduce una evolución importante en el plano de selección de capacidad: ahora un scale set puede exponer múltiples labels para emparejar jobs con combinaciones de atributos. Para equipos que separan cargas por compliance (por ejemplo, runners en red privada + clase de nodo dedicada + toolchain específica), esto permite diseñar un mapeo más limpio entre requisitos de workflow y pools de ejecución.
El cambio al cliente actions/scaleset también tiene implicancias de ingeniería de plataforma: estandariza la forma de interactuar con APIs de scale set y reduce dependencia de código interno no reutilizable. En términos prácticos, habilita construir controladores satélite o automatizaciones de capacity planning con menor riesgo de desviarse del comportamiento oficial del ecosistema GitHub.
Los charts Helm experimentales merecen atención en ambientes de staging: ofrecen una interfaz más coherente para etiquetado/anotaciones y ajustes de despliegue, pero al ser experimentales conviene evaluarlos con pruebas de regresión antes de moverlos a producción. Finalmente, la lógica que detiene autoscaling frente a runner sets desactualizados puede mejorar la higiene operativa, aunque su efectividad completa depende de la disponibilidad del cambio asociado en versiones de runner.
Qué deberían hacer los administradores o equipos técnicos
- Evaluar upgrade controlado a ARC 0.14.0 en un clúster de preproducción, validando compatibilidad de charts, políticas y workflows críticos.
- Rediseñar estrategia de labels en scale sets para aprovechar multilabel y reducir proliferación de pools.
- Definir estándar de metadata (labels/annotations) para recursos internos de ARC alineado a observabilidad, seguridad y chargeback.
- Revisar políticas de autoscaling y lifecycle ante runners desactualizados, incluyendo alertas cuando ARC desactive escalado.
- Probar scheduling en clusters mixtos y confirmar que listeners queden en nodos Linux según política esperada.
- Instrumentar métricas operativas: tiempo de provisión de runners, tasa de fallos de jobs por infraestructura, churn de pods, backlog de cola y costo por ejecución.
- Documentar runbooks de rollback para volver a versión previa de controlador/charts si aparecen regresiones durante la adopción.
Conclusión
ARC 0.14.0 no cambia la premisa central de los runners self-hosted en Kubernetes, pero sí mejora varios puntos donde históricamente se acumula deuda operativa: etiquetado rígido, integración limitada, metadatos inconsistentes y escalado en estados no deseados. Para equipos que administran CI/CD como plataforma compartida, estos ajustes pueden traducirse en menos complejidad y mejor confiabilidad.
La recomendación práctica es tratar esta versión como una oportunidad de saneamiento operativo, no solo como un upgrade técnico. Aprovechar multilabel, ordenar metadatos, reforzar observabilidad y validar escenarios de autoscaling permitirá capturar valor real del release y reducir riesgos en pipelines productivos.
Fuentes
- GitHub Changelog: ARC 0.14.0
- Release notes de actions-runner-controller v0.14.0
- Documentación oficial de ARC