AWS incorporó soporte de Dynamic Resource Allocation (DRA) para Neuron en Amazon EKS y cambia cómo se programan cargas con Trainium e Inferentia: menos lógica específica en manifests, mejor uso de topología y más control operativo para equipos de plataforma.
Introducción
La adopción de aceleradores para entrenamiento e inferencia ya no es un caso aislado: hoy forma parte de plataformas compartidas donde conviven cargas de datos, APIs, pipelines de CI/CD y servicios de observabilidad. En ese contexto, la novedad de AWS Neuron para Amazon EKS —soporte de Dynamic Resource Allocation (DRA)— es más que un cambio de API: redefine cómo los equipos de plataforma asignan hardware especializado sin trasladar complejidad a cada equipo de ML.
Hasta ahora, muchos despliegues con Trainium e Inferentia dependían de device plugins, extensiones de scheduler y convenciones internas para “encajar” topología, afinidad y restricciones del hardware. El resultado habitual era fricción operativa: manifests difíciles de mantener, baja portabilidad entre clusters y mayor riesgo de sobreaprovisionar nodos caros. DRA apunta justamente a ese punto de dolor.
Qué ocurrió
AWS anunció el driver Neuron DRA para EKS, con soporte para scheduling nativo y consciente de topología en instancias basadas en Trainium. Según la documentación oficial de EKS, el enfoque recomendado para nuevos despliegues en Kubernetes 1.34+ pasa a ser DRA, mientras el modelo basado en device plugin continúa soportado para escenarios existentes.
El cambio técnico más relevante es que el scheduler deja de trabajar solo con contadores enteros de recursos extendidos y puede tomar decisiones con atributos más ricos publicados vía ResourceSlice. Esto incluye información sobre tipo de instancia, versión de driver, agrupación de dispositivos conectados y afinidad con red/EFA en ciertos casos.
Impacto para DevOps / Infraestructura / Cloud / Seguridad
Para equipos de DevOps y platform engineering, el impacto principal es la separación de responsabilidades. Infraestructura puede definir DeviceClass y ResourceClaimTemplate reutilizables; los equipos de aplicación consumen esos contratos sin tener que codificar detalles de hardware en cada deployment. Esa división reduce drift entre entornos y simplifica el gobierno técnico.
En términos de cloud cost y capacidad, DRA mejora la probabilidad de ubicar workloads donde realmente existe el subset de dispositivos requerido (por ejemplo, grupos conectados), evitando ciclos de reintento y nodos ociosos. Para operaciones SRE, menos “pod pending por constraints implícitas” suele traducirse en menor tiempo de diagnóstico y menos alertas ruidosas.
En seguridad y compliance técnico, aunque la novedad no es una mitigación de CVE, sí mejora trazabilidad operativa: la intención de consumo de aceleradores queda declarada en claims y clases de dispositivo, en lugar de dispersa en anotaciones y reglas ad hoc. Eso facilita auditorías de plataforma y revisiones de cambios.
Detalles técnicos
DRA en Kubernetes usa recursos del grupo resource.k8s.io/v1, en especial DeviceClass, ResourceClaim, ResourceClaimTemplate y ResourceSlice. Con Neuron DRA, AWS expone una clase de dispositivo (neuron.aws.com) y permite selección por atributos usando CEL, además de modos de asignación como All o ExactCount.
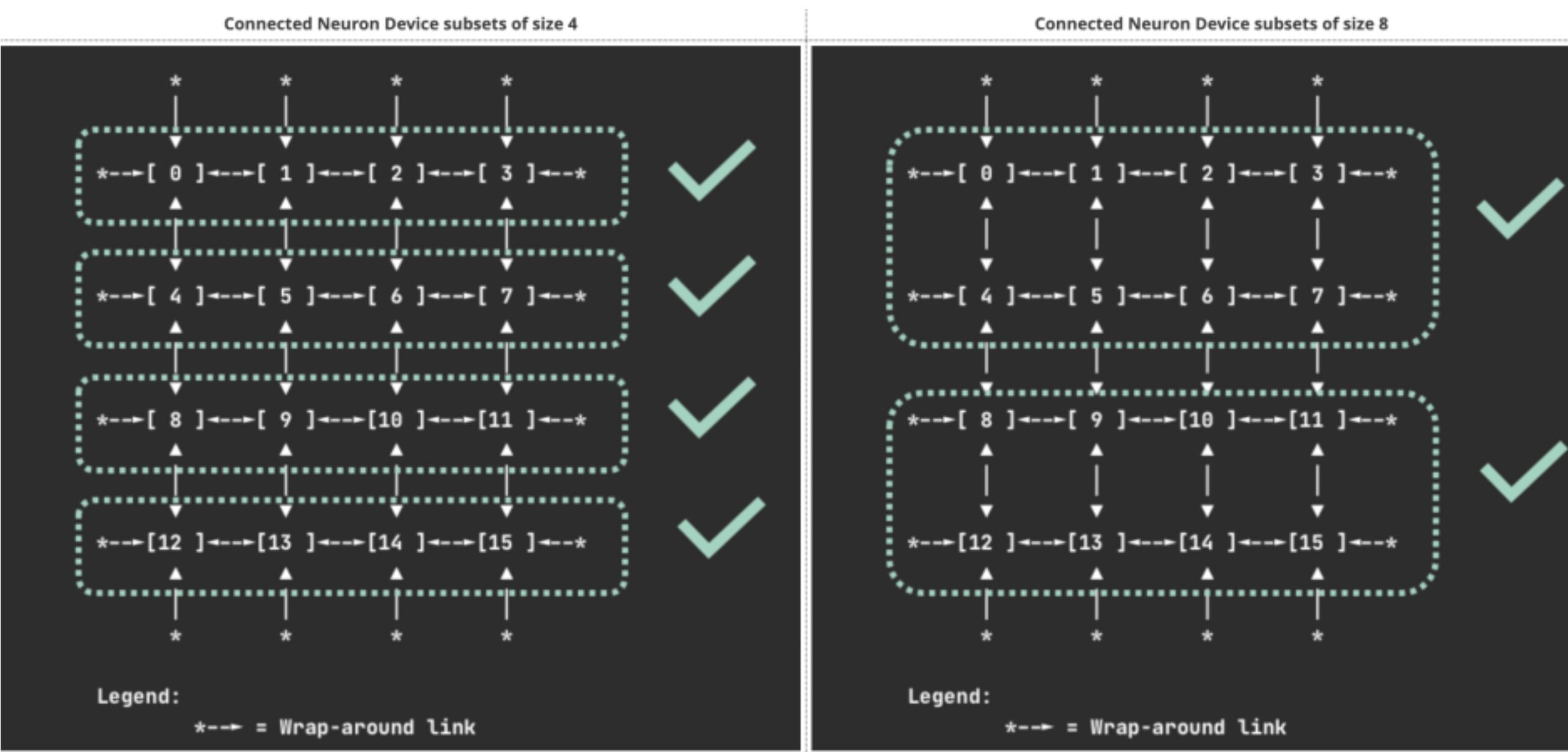
Un punto operativo importante es el soporte de subconjuntos conectados de dispositivos (1, 4, 8 o 16), que evita depender de extensiones externas para ciertos patrones de asignación contigua. También aparece la configuración por workload de Logical NeuronCore (LNC), útil para ajustar consumo sin preconfigurar toda la flota mediante launch templates.
La guía de EKS también marca limitaciones que hay que considerar en diseño: DRA exige versiones recientes de Kubernetes y no debe convivir en el mismo nodo con el modelo tradicional de device plugin para Neuron. En consecuencia, una migración ordenada requiere estrategia por node groups o por clusters, no “mezcla parcial” sin aislamiento.
Desde la perspectiva de arquitectura, este movimiento alinea EKS con la madurez de DRA en Kubernetes (ya estable en versiones recientes) y abre la puerta a patrones más declarativos para aceleradores, similares a lo que el ecosistema ya adoptó con storage dinámico años atrás.
Qué deberían hacer los administradores o equipos técnicos
- Inventariar workloads de Neuron: identificar cuáles dependen hoy de device plugin/scheduler extension y cuáles podrían migrar a DRA sin cambios de aplicación.
- Definir una política de transición: separar node groups para DRA y legado, evitando coexistencia de ambos mecanismos en los mismos nodos.
- Estandarizar ResourceClaimTemplates: crear plantillas por perfil (entrenamiento distribuido, inferencia online, batch) para reducir variabilidad entre equipos.
- Agregar observabilidad de asignación: medir tiempos de scheduling, tasa de pods pendientes y utilización efectiva de aceleradores antes/después de migrar.
- Actualizar runbooks: incluir troubleshooting específico de
ResourceSlice,DeviceClassy validaciones de versión de cluster/AMI. - Planificar impacto en autoscaling: validar compatibilidad del stack de provisioning (incluido Karpenter si aplica) antes de promover a producción.
Conclusión
El anuncio de Neuron DRA en EKS no es solo una mejora incremental para IA en AWS; es una señal de madurez operacional. Llevar la asignación de aceleradores a un modelo declarativo y nativo de Kubernetes reduce deuda técnica y mejora la gobernanza de plataforma en entornos donde el costo y la disponibilidad de hardware son críticos.
Para equipos que ya operan Trainium/Inferentia, el valor está en diseñar una migración controlada que priorice consistencia y observabilidad. Para quienes recién comienzan, DRA ofrece una base más limpia desde el día uno: menos pegamento ad hoc y más contratos explícitos entre infraestructura y workloads.
Fuentes
- AWS Neuron announces support for Dynamic Resource Allocation with Amazon EKS
- Manage Neuron devices on Amazon EKS
- Dynamic Resource Allocation | Kubernetes Docs