Bajada: AWS habilitó Cluster Insights directamente en la consola de OpenSearch Service y añadió publicación de insights vía EventBridge. El cambio reduce fricción operativa para equipos SRE/DevOps al consolidar diagnóstico, recomendaciones y automatización en un mismo flujo.
Introducción
Amazon OpenSearch Service incorporó una mejora con impacto operativo real para equipos que administran clusters en producción: Cluster Insights ahora se puede consultar desde la consola de AWS y, además, los insights se publican como eventos en Amazon EventBridge. Aunque no cambia el motor de búsqueda en sí mismo, sí cambia la forma de operar incidentes, prevenir degradaciones y automatizar respuestas sobre dominios OpenSearch.
En términos prácticos, el anuncio apunta a un problema clásico de operaciones: tener métricas en un lado, recomendaciones en otro, y automatización en un tercero. Con esta actualización, AWS acerca esas tres capas y baja el costo de coordinación entre equipos de plataforma, observabilidad y seguridad.
Qué ocurrió
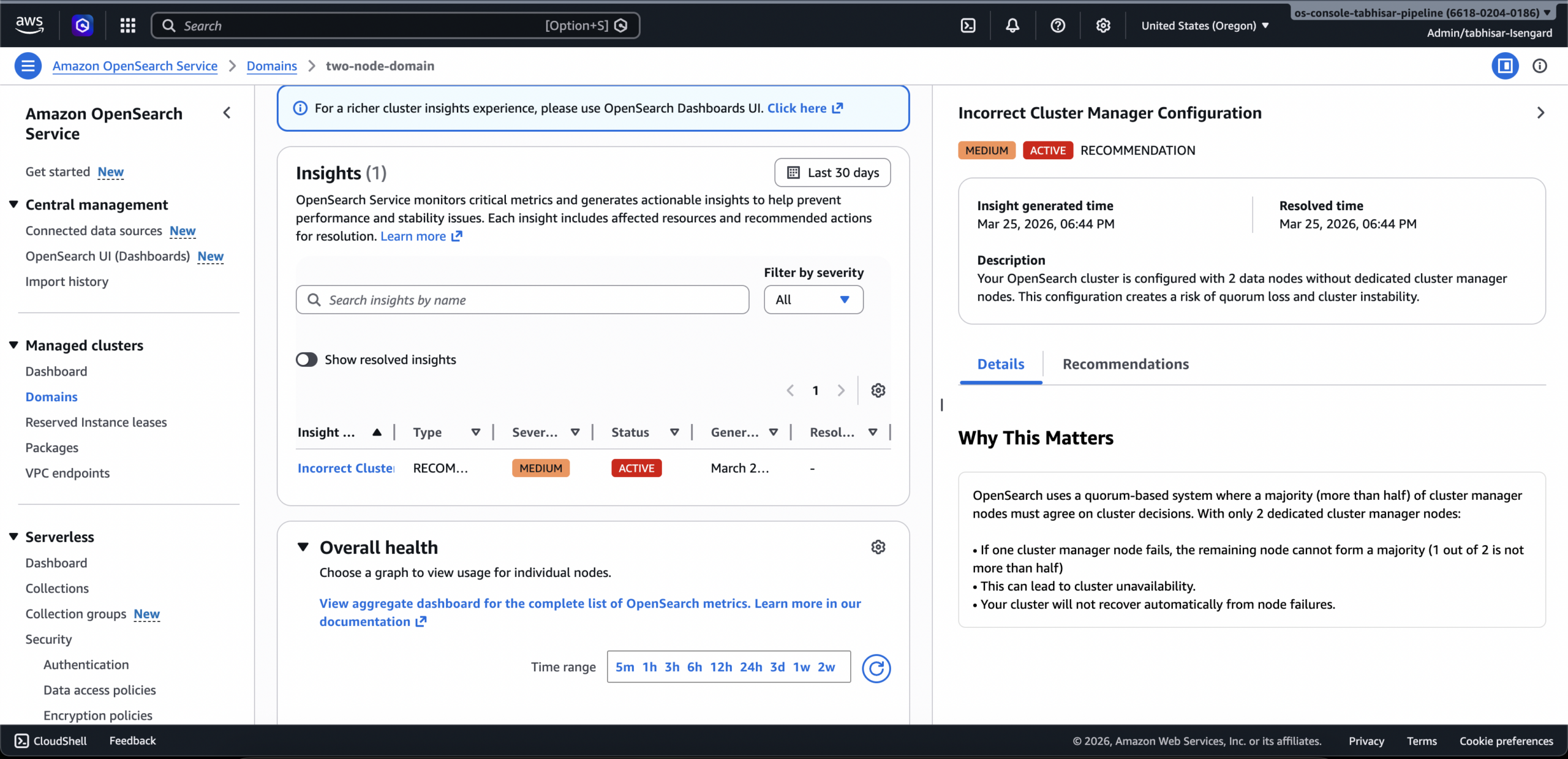
El 30 de marzo de 2026, AWS anunció que Cluster Insights está disponible dentro de la consola de Amazon OpenSearch Service, en paralelo con su disponibilidad previa en OpenSearch UI Dashboards. También informó que estos insights pueden emitirse como eventos en EventBridge, para integrarse con flujos automáticos de notificación y remediación.
Según la documentación oficial, Cluster Insights está disponible sin costo adicional para dominios con OpenSearch 2.17 o superior (y con requerimientos de service software al día para algunas versiones). La funcionalidad incluye visualización del estado del clúster, tendencias de incidentes, severidad, recomendaciones accionables y vista por nodo/índice/shard; en versiones más nuevas también agrega query insights más profundos.
Impacto para DevOps / Infraestructura / Cloud / Seguridad
Para operaciones cloud, el valor principal es la reducción del MTTR y del tiempo de triage. En lugar de depender exclusivamente de paneles dispersos, los equipos pueden detectar condiciones de riesgo (por ejemplo, shards sobredimensionados, presión de recursos o configuraciones fuera de buenas prácticas) desde una vista unificada, con contexto y pasos sugeridos.
Para SRE y platform engineering, la salida por EventBridge es igual de relevante: permite convertir señales técnicas en flujos automáticos. Un insight crítico puede disparar una regla que abra ticket, envíe alerta a un canal operativo, ejecute una Lambda de diagnóstico o active una Step Function para acciones de mitigación controladas.
En seguridad y compliance técnico, la mejora también suma. Varias recomendaciones de Cluster Insights están asociadas a resiliencia y hardening operativo, y el hecho de tratarlas como eventos auditables facilita gobierno, trazabilidad y controles de proceso.
Detalles técnicos
La documentación de OpenSearch Service detalla que Cluster Insights consolida señales de salud operativa y recomendaciones, incluyendo:
- estado general del clúster (green/yellow/red),
- tendencia de insights en una ventana histórica,
- priorización por severidad,
- métricas de cluster, nodo, índice y shard,
- mapa de recursos afectados y guía de remediación.
En dominios compatibles, la capacidad de Query View permite identificar consultas de alto costo (latencia, CPU, memoria), con foco en optimización. Esto es especialmente útil para cargas mixtas de ingestión y búsqueda donde los cuellos de botella no siempre son obvios con métricas agregadas.
Por el lado de integración, OpenSearch Service ya emitía diversos eventos operativos en EventBridge (actualizaciones de software, Auto-Tune, salud del clúster, entre otros). La novedad es incorporar también el monitoreo de insights dentro de ese patrón, lo que simplifica orquestar respuestas automáticas basadas en reglas.
Desde diseño operativo, este enfoque encaja bien con una arquitectura de “detección en plataforma + reacción en workflow”: la plataforma identifica riesgo, EventBridge enruta, y servicios de ejecución (Lambda, Step Functions, SQS/SNS) aplican playbooks según severidad y criticidad del dominio.
Qué deberían hacer los administradores o equipos técnicos
- Verificar prerequisitos: confirmar versión de OpenSearch (2.17+) y service software actualizado donde aplique.
- Definir severidades operativas: mapear qué tipos de insights generan alertas, tickets o acciones automáticas.
- Crear reglas en EventBridge: separar rutas para “informacional”, “alto” y “crítico”, evitando sobrealerta.
- Conectar runbooks: asociar cada clase de insight a un playbook técnico reproducible (diagnóstico, mitigación, rollback).
- Medir efectividad: antes y después de habilitar el flujo, comparar MTTR, tasa de incidentes repetidos y ruido de alertas.
- Ajustar gobierno: registrar eventos y decisiones para auditoría operativa y revisiones postmortem.
Conclusión
Un punto adicional para equipos con operación 24×7: esta integración favorece una estrategia de «operación por políticas». En vez de depender únicamente de revisión manual de dashboards, se pueden definir umbrales por tipo de dominio (crítico, estándar, sandbox) y encadenar respuestas proporcionales. Eso ayuda a reducir fatiga de alertas, mejora consistencia entre turnos y permite escalar prácticas SRE sin duplicar esfuerzo humano.
La actualización de Cluster Insights no es un “feature cosmético”: mejora el ciclo operativo completo de OpenSearch al unir visibilidad, recomendación y automatización. Para equipos que operan clusters críticos, el mayor beneficio está en acortar diagnóstico y estandarizar respuesta ante degradaciones.
En un contexto donde observabilidad sin acción se queda corta, la combinación consola + EventBridge va en la dirección correcta: menos fricción entre detectar y actuar, y más capacidad de operar OpenSearch con disciplina SRE.
Fuentes
- https://aws.amazon.com/about-aws/whats-new/2026/03/access-cluster-insights-opensearch/
- https://docs.aws.amazon.com/opensearch-service/latest/developerguide/cluster-insights.html
- https://docs.aws.amazon.com/opensearch-service/latest/developerguide/monitoring-events.html