AWS Batch incorporó dos capacidades operativas que cierran una brecha frecuente en entornos de cómputo por lotes: visibilidad explícita del estado de AMIs administradas por el servicio y notificaciones de cambios planificados vía AWS Health con integración a EventBridge. Para equipos de plataforma y SRE, esto convierte actualizaciones de imagen y deprecaciones de infraestructura en procesos más predecibles y automatizables.
Introducción
AWS Batch sumó una mejora que, aunque parece incremental, tiene impacto directo en la operación diaria de equipos que ejecutan cargas batch de forma sostenida. Desde el 25 de marzo de 2026, el servicio expone el estado de AMIs por entorno de cómputo y además publica eventos de ciclo de vida planificados en AWS Health. En términos prácticos, esto reduce una de las principales fuentes de deuda operativa en plataformas batch: enterarse tarde de cambios de imagen o deprecaciones que terminan forzando actualizaciones apuradas.
Para organizaciones con decenas o cientos de compute environments, el problema no suele ser “cómo actualizar”, sino “cuándo actualizar” y “cómo detectar en qué entornos hay riesgo”. La novedad de AWS Batch apunta exactamente a eso: pasar de un modelo reactivo a uno de monitoreo continuo con gatillos de automatización.
Qué ocurrió
AWS anunció dos funciones nuevas para Batch. La primera es un indicador de estado de AMI en los compute environments administrados por el servicio. Ese estado informa, al menos, si el entorno está en LATEST (al día) o UPDATE_AVAILABLE (hay nueva imagen recomendada). La segunda es el soporte de AWS Health Planned Lifecycle Events, que agrega avisos anticipados ante cambios relevantes, por ejemplo deprecaciones de AMIs base o transiciones de sistema operativo.
El objetivo conjunto es dar visibilidad previa para planificar cambios sin interrumpir operación productiva. AWS también confirmó que la disponibilidad es global en regiones donde Batch está soportado.
Impacto para DevOps / Infraestructura / Cloud / Seguridad
El impacto principal está en confiabilidad operativa y gobierno de plataforma. En muchos equipos, las AMIs de Batch se actualizan solo cuando hay incidentes, hallazgos de seguridad o tickets atrasados. Con esta mejora, el dato de obsolescencia pasa a ser observable y accionable, lo que permite incorporar controles preventivos en pipelines y tableros de salud de infraestructura.
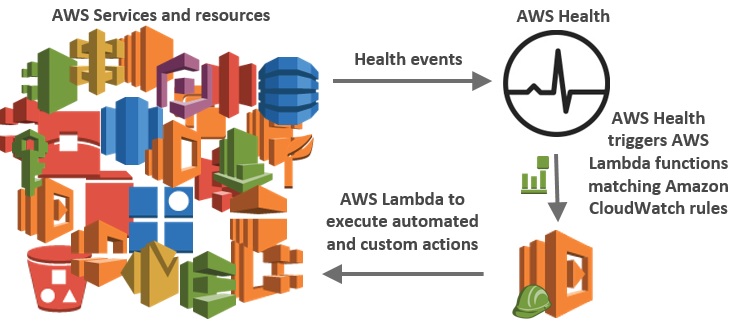
Desde seguridad, la mejora también es relevante porque acelera el cierre de ventanas de exposición asociadas a imágenes desactualizadas. No elimina la necesidad de hardening ni validación, pero sí reduce el tiempo en que un entorno puede quedar fuera de baseline sin que nadie lo vea. Desde SRE, la integración con AWS Health + EventBridge facilita integrar estos cambios con procesos existentes de alerting, gestión de cambios y creación de tickets.
Detalles técnicos
Según la documentación de AWS Batch, el estado de imagen puede consultarse desde consola y vía API/CLI con describe-compute-environments. Cuando hay actualización disponible, el servicio permite promover AMI al último baseline usando la opción de actualización correspondiente, sin necesidad de fijar manualmente IDs en escenarios administrados por AWS Batch.
Un punto técnico clave es que este tipo de actualización dispara infrastructure updates, no simples cambios de escala. Eso implica reemplazo de instancias y potencial interrupción de jobs en ejecución según la política configurada. En entornos con estrategia BEST_FIT, AWS recomienda blue/green para minimizar impacto.
En paralelo, los eventos planificados de ciclo de vida llegan por AWS Health como scheduledChange, con lead time de referencia de 90 a 180 días cuando es posible. La lista de recursos afectados se actualiza con estados como PENDING y RESOLVED, útil para seguimiento de migración por cuenta y por región. AWS también aclara que esta resolución puede tardar hasta 72 horas en reflejarse.
Para automatización, los eventos de Health se pueden enrutar por EventBridge a Lambda, SNS, SQS o flujos internos. Un patrón típico para Batch filtra por source: aws.health, detail.service: BATCH y eventTypeCategory: scheduledChange. Esto habilita playbooks prácticos: crear incidentes de cambio, notificar a canales de operaciones, o ejecutar chequeos previos de compatibilidad de AMI.
Qué deberían hacer los administradores o equipos técnicos
- Inventariar compute environments: identificar cuáles usan AMIs administradas por Batch y cuáles dependen de AMIs custom, porque el nivel de visibilidad no es el mismo.
- Operacionalizar el estado de AMI: incluir batchImageStatus en dashboards y controles periódicos para detectar desvíos temprano.
- Definir ventana de mantenimiento explícita: tratar updates de AMI como cambio de infraestructura, con retry policy y estrategia de continuidad para jobs largos.
- Automatizar notificaciones de lifecycle: crear reglas EventBridge para eventos de AWS Health y conectar con ticketing/chatops.
- Probar blue/green en staging: especialmente en entornos con dependencia de librerías nativas, drivers o jobs sensibles al runtime.
- Alinear seguridad y plataforma: usar los eventos planificados como entrada formal para patch cadence y compliance técnico.
Conclusión
La novedad de AWS Batch no es solo una mejora de UX. Es un cambio operativo que ayuda a transformar mantenimiento reactivo en gestión predecible de ciclo de vida. El estado de AMI reduce la opacidad sobre desactualización real, y los eventos planificados de AWS Health agregan la anticipación necesaria para planificar migraciones sin sobresaltos.
Para equipos de DevOps, SRE e infraestructura, la oportunidad está en integrar estas señales en procesos existentes: observabilidad, gestión de cambios y automatización de respuesta. Quienes lo hagan temprano van a reducir interrupciones por cambios tardíos y mejorar su postura de resiliencia en cargas batch productivas.
Fuentes
- AWS Batch now provides AMI status and supports AWS Health Planned Lifecycle Events
- AWS Batch User Guide: Managing AMI versions
- AWS Batch User Guide: Planned lifecycle events