Si son sysadmins, necesitarán alguna forma de ver cómo se utilizan los recursos de nuestros sistemas, sobre todo cuando las cosas andan mal. Ver estadísticas sobre el uso de recursos permite tomar varias decisiones, como comprar hardware, separar servicios, virtualizar, o para solucionar errores en caso de procesos glotones, entre otras cosas.
Si bien en GNU/Linux todas las estadísticas se almacenan en el /proc, es necesario contar con alguna herramienta que las interprete y las haga más amigables. Para ello, contamos con sysstat, un paquete que provee varias herramientas para monitorear la performance del sistema y el uso de recursos.
Los componentes más interesantes de sysstat son:
– sar: reúne, reporta y almacena información de actividad del sistema (CPU, memoria, discos, interrupciones, interfaces de red, TTY, tablas del kernel, etc). Esta herramienta provee muchas opciones para filtrar los datos que deseamos obtener, y permite almacenar los resultados en archivos binarios que luego se pueden visualizar con el mismo sar. Es posible indicar la cantidad de muestras a tomar y el intervalo de tiempo entre muestras.
– sadc (system activity data collector): se encarga de recoger información del sistema una dada cantidad de veces, a intervalos específicos de tiempo, y se utiliza como backend de sar. Escribe en formato binario en un dado archivo o en la standar output. Si no se especifica la cantidad de muestras a tomar, éste escribe infinitamente.
– sa1: un shell script que utiliza sadc para generar el archivo binario /var/log/sa/sadd o /var/log/sysstat/sadd (donde dd es el día del mes, por ejemplo sa16 indica el día 16). Este script está designado para utilizarse con cron (ver /etc/cron.d/sysstat).
– sa2: otro shell script que utiliza sadc para generar reportes diarios en el archivo binario /var/log/sa/sardd o /var/log/sysstat/sardd (donde dd es el día del mes). Este script también está designado para utilizarse con cron (ver /etc/cron.daily/sysstat).
– sadf: permite mostrar el contenido de archivos binarios sar en diferentes formatos (CSV, XML, etc). El formato de salida default es uno fácilmente parseable por diferentes herramientas shell como grep, awk, sed, etc.
– pidstat: reporta estadísticas de procesos como uso de CPU, memoria, I/O, etc. Como en sar, es posible indicar la cantidad de muestras y el intervalo de tiempo entre muestras.
Si deseamos medir la utilización de recursos en el server, lo mejor es dejar que sa1 y sa2 generen los correspondientes logs durante un día, una semana, un mes o el tiempo que quieran, y luego visualizarlos con sar. Por defecto las muestras se toman cada 10 minutos, lo cual provee un buena visión sobre como se utilizan los recursos.
Otra posibilidad es ejecutar sar con el parámetro «-o archivo» para almacenar los datos en un archivo binario, e indicarle el intervalo de segundos entre muestras y la cantidad de muestras a tomar. Por ejemplo, el siguiente comando almacena todos los datos de utilización de recursos en el archivo «revision» cada 5 minutos:
sar -A -o revision 300
Para poder parsear el archivo recién generado con sar, es necesario utilizar el parámetro -f, por ejemplo:
sar -A -f revision
En la mayoría de los casos lo que necesitamos visualizar es uso de memoria, CPU, disco, swap y red. Todo esto se puede hacer con el siguiente comando:
sar -rudpW -n DEV,SOCK
donde:
-r muestra uso de memoria
-u muestra uso de CPU
-d muestra uso de disco
-p imprime el nombre de los dispositivos de forma agradable (usado con -d)
-W muestra estadísticas de swap
-n DEV,SOCK muestra estadísticas de las interfaces de red y cantidad de sockets utilizados.
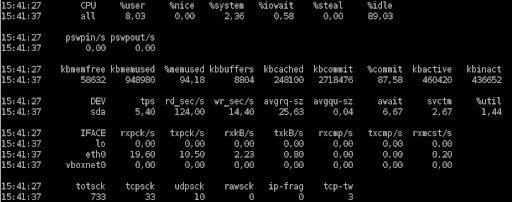
Si no se utiliza el parámetro -f, sar toma los datos de los logs generados por sa1 y sa2. En caso de utilizar un archivo binario generado con sar (por ejemplo revision), pueden usar el siguiente comando:
sar -rudpW -n DEV,SOCK -f revision
Como podrán observar, la salida de sar no es muy amigable para ser filtrada y/o graficada y/o almacenada en una base de datos, así que lo mejor es utilizar sadf. sadf provee un set de opciones propias y permite utilizar las opciones de sar luego de dos giones (–). Entre las opciones propias de sadf, son interesantes:
-d imprime la salida con los campos separados con punto y coma (;)
-D igual a -d pero utiliza timestamp en lugar de fechas human friendly
-h para imprimir los resultados en una sola línea
-p salida default, amigable para los parsers
-x imprime la salida en formato XML
El comando del ejemplo anterior, utilizando sadf para ser parseado fácilmente, quedaría:
sadf — -rudpW -n DEV,SOCK
o con -h para separar fácilmente los campos en una planilla (Calc, Excel, etc)
sadf -h — -rudpW -n DEV,SOCK
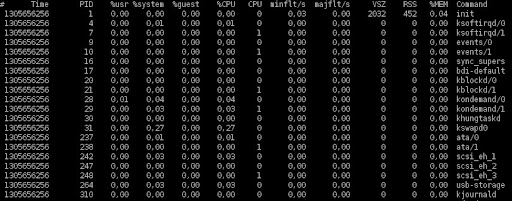
Además de las estadísticas anteriores, para hilar más fino a la hora de ver quién gasta los recursos, es necesario tener estadísticas de los procesos que se están ejecutando. Para ello contamos con pidstat, cuyos datos arrojados son similares a los de sar, pero por proceso. pidstat acepta varios argumentos para mostrar distintas estadísticas, pero para una vista básica, me alcanza la siguiente configuración:
pidstat -ru -h 300 | sed ‘1,2d’
donde:
-r muestra uso de memoria
-u muestra uso de CPU
-h muestra las estadísticas horizontalmente (todo en una sola tabla).
300 es el intervalo de tiempo (en segundos) para tomar muestras
sed ‘1,2d’ elimina las primeras dos líneas de la salida (son un comentario y una línea en blanco)
pidstat no ofrece la opción de crear un archivo binario para almacenar los datos, por lo cual debemos redirigir la salida a un archivo para poder filtrarla luego.
Si lo que quieren son gráficos de utilización (siempre algo visual ayuda a captar mejor los datos), podemos utilizar la salida de sadf y graficar con Calc (o Excel), con gnuplot, o con la interesante Sysstat Graph. No tuve la oportunidad de probar esta última, pero aparenta ser muy útil. Está escrita en PHP, por lo cual es fácil de instalar.
Referencias
– Sysstat man
– How do I Find Out Linux CPU Utilization?