![]() Ayer apareció en todos los medios de comunicación, aunque yo me enteré por el grupo de escalabilidad en español (toma promo gratuita). Una compañía de Miami, LexisNexis ha anunciado que hará Open Source su tecnología de computación y análisis de datos HPCC Systems (High Performance Computing Cluster) a la que la prensa no ha dudado en tildar como el Hadoop Killer.
Ayer apareció en todos los medios de comunicación, aunque yo me enteré por el grupo de escalabilidad en español (toma promo gratuita). Una compañía de Miami, LexisNexis ha anunciado que hará Open Source su tecnología de computación y análisis de datos HPCC Systems (High Performance Computing Cluster) a la que la prensa no ha dudado en tildar como el Hadoop Killer.
Investigando algo más descubrimos que LexisNexis es una empresa que lleva bastante tiempo en el sector, más de 30 años, y que compró esta tecnología en el 2004 a otra empresa llamada Seisint que empezó su investigacíon en el 1999. Es una empresa que se dedica principalmente al ámbito legal y financiero, pero parece que han visto una buena oportunidad en el ámbito de la computación de alto rendimiento. He buscado referencias de HPCC pero no las he podido encontrar, salvo un puñado de citas sin nombre en la caché de Google, pero lo que sería LexisNexis sí que opera a nivel global con más de 450 clientes en 100 países.
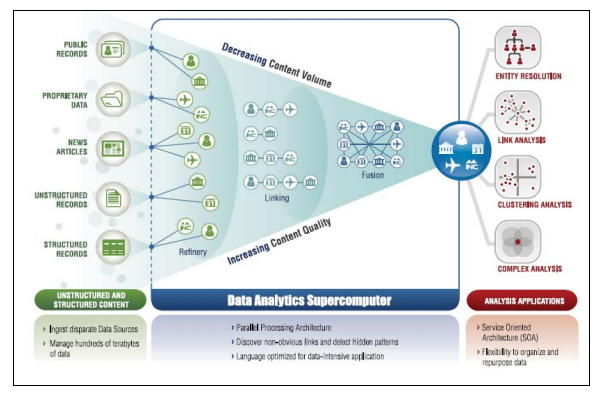 En este enlace podéis encontrar un paper sobre la arquitectura de HPCC donde se puede apreciar que se basa en la construcción de clusters en máquinas linux normales y corrientes a las que se añaden los servicios y aplicaciones de HPCC.
En este enlace podéis encontrar un paper sobre la arquitectura de HPCC donde se puede apreciar que se basa en la construcción de clusters en máquinas linux normales y corrientes a las que se añaden los servicios y aplicaciones de HPCC.
El desarrollo de programas para HPCC se realiza utilizando un lenguaje propio que han llamado ECL (Enterprise Data Control Language). Siguiendo un poco el paper, vemos que HPCC se divide básicamente en el sistema de procesado de trabajos batch en el cluster y por otra parte el sistema de indexación y análisis de datos que definen como un sistema similar a un datawarehouse funcionando en paralelo, que ofrece servicios web a los desarolladores y tiempos de respuesta de menos de un segundo. Copio del paper:
A Roxie cluster is similar in its function and capabilities to Hadoop with HBase
and Hive capabilities added, but provides significantly higher throughput since it uses a more optimized execution environment and filesystem for high-performance online
processing.
Desde luego a primera vista resulta prometedor. Aunque a mi me ha dado que pensar. En especial por el despliegue de bombos y fanfarrias en los diferentes medios. En TheRegister por ejemplo podemos leer: «Since it’s written in C++, he says, the system is also faster than Hadoop, which is written in Java.». Mi aprecio por Java se ha ido diluyendo con el tiempo, pero este tipo de afirmaciones no tienen ninguna consistencia (para los que no sepan de que hablo, este libro por ejemplo explica muchos casos en los que Java, o cualquier otro lenguaje compilado en tiempo real, puede ser fácilmente más rápido que lenguajes compilados tradicionales como C++).
En su página web afirman rotundamente que su rendimiento es 4x más rápido que Hadoop. En el grupo de escalabilidad, gente que sabe más que yo, dice que no lo ve tan raro, así que yo me creo que es mejor, aunque deberían proporcionar algo más de detalle que lo que ponen en su web ya que de otro modo no deja de ser publicidad.
Así que nada. Bienvenidas sean las alternativas y más si son Open Source. ¿Alguien que lo piense probar?